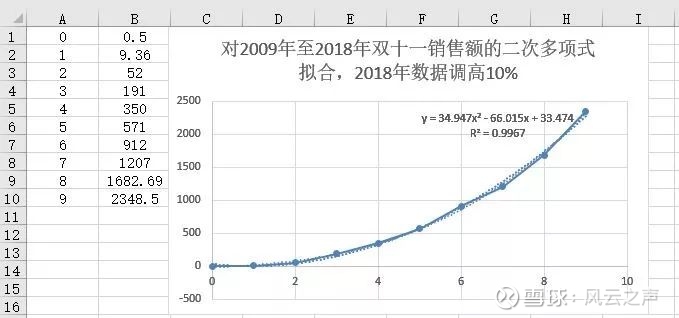
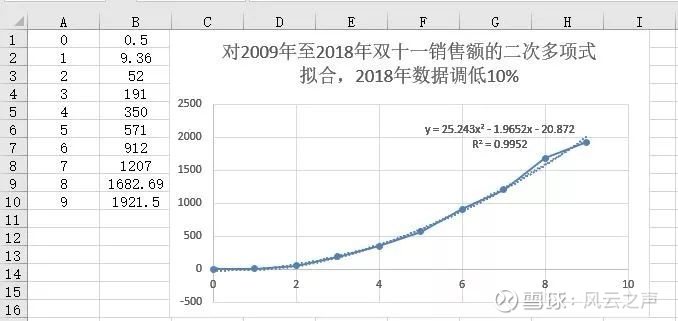
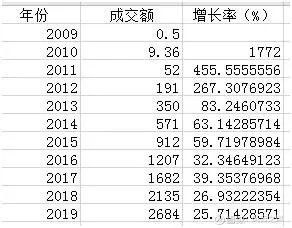
所谓拟合,就是寻找一条曲线,使它尽可能地靠近已知的若干个点。什么叫做“尽可能靠近”呢?最容易想到的判据是,每一点的真实值和拟合值之间都有个误差,令这些误差的绝对值之和最小。但这样在数学上不容易处理,因此真正常用的判据是,令这些误差的平方和最小。由此推出的算法,叫做最小二乘法(method of least squares)。
在数据分析中,拟合是一个相当有用的工具。但为了向人们提醒它的局限性,伟大的数学家冯·诺依曼(John von Neumann,1903 - 1957)有一句名言:
冯·诺依曼
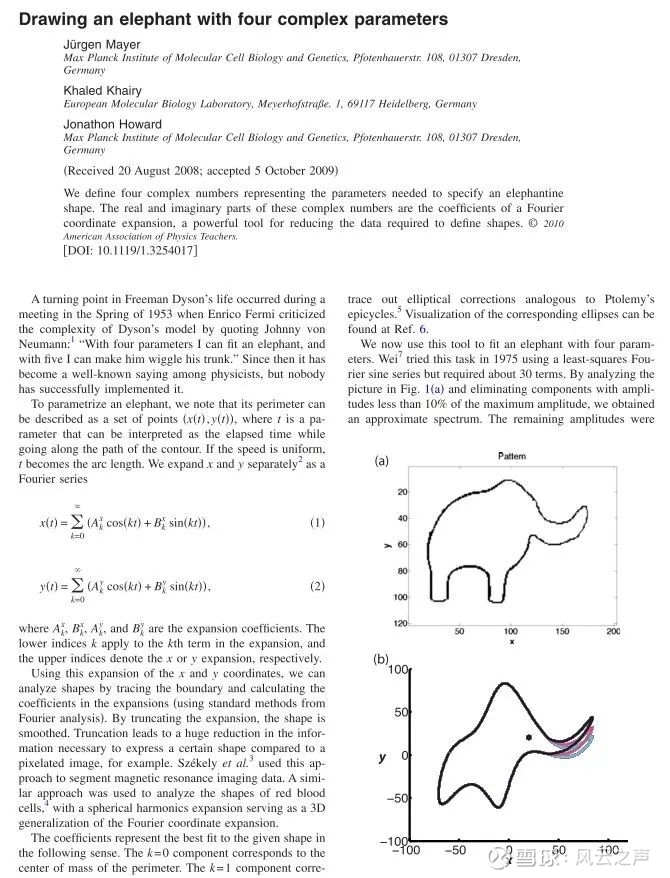
“用四个参数我可以拟合出一头大象,而用五个参数我可以让它的鼻子摇起来。”
这话最初只是开玩笑,但后来真有人去研究如何用四个参数拟合大象,而且还真让他们给研究出来了(网页链接)。2010年6月,尤根·迈尔(Jürgen Mayer)等三位德国分子生物学家在《美国物理学期刊》(American Journal of Physics)发表了一篇文章,标题是《用四个复参数画出一头大象》(Drawing an elephant with four complex parameters)。他们发现,用四个复参数可以大致勾勒出大象的形状,再引入一个复参数就可以让大象的鼻子摆动起来(网页链接)。
其实最最关键的问题是,高拟合有吮马用?高拟合 = 准确预测?如果为了解释已经发生的事情,那是在做一个解释型的模型,这种情况下你可以尽情地往里面扔features,以最大限度提高拟合度(R2),但是这种工作基本上没有太大 value adding。真正需要的是 predictive model,这种情况下过于追求高拟合度反而可能导致 overfitting,进而导致 the model does not generalize well on new auidence